


From Intelligent Document Processing to Scalable Ingestion: Introducing the PolarSled Ingestion Framework Powered by Openflow
In the previous blog, you learned how Openflow simplifies AI-powered document processing by abstracting away the complexities of ingestion, parsing, chunking, and vectorization for unstructured data. In this blog, you will take a deeper dive into the technical architecture that enables this transformation at scale. I will introduce the PolarSled Ingestion Framework, a metadata-driven solution built on top of Openflow. It is designed for enterprise-grade data ingestion across all formats and incorporates built-in logging and alerting mechanisms to ensure quick detection and response to pipeline failures.
Scaling ingestion pipelines across diverse data types
Data engineering teams often face several persistent challenges that impede efficiency and innovation:
- Time-consuming pipeline development: Building ingestion pipelines from scratch involves hours of manual coding and debugging, especially when integrating real-time application programming interface (API) data with batch processing systems. The synchronization between these two modes can be intricate.
- Diversity in data sources: Integrating data from heterogeneous sources such as APIs, databases, portable document format (PDF) files, and images often demand custom connectors. For instance, using optical character recognition (OCR) to extract data from scanned documents may not align well with tabular database structures without additional preprocessing.
- Limited governance and visibility: Tracing the origin and transformation of curated data is challenging without proper data lineage, which raises compliance risks and complicates audits.
- Distraction from high-value work: Engineers often spend valuable time fixing extraction, transformation, and loading (ETL) issues or managing integration scripts—diverting attention from strategic initiatives like predictive modeling or AI-powered document processing.
To address these challenges, a solution is needed to resolve the pain points effectively, which is user-friendly and extensible. This will allow seamless support for the ingestion of new data sources.
The solution: PolarSled Ingestion Framework–A metadata-first approach
The PolarSled Ingestion Framework is a Snowflake-native ingestion framework developed by LTIMindtree to streamline and standardize data ingestion. Built on Openflow’s capabilities[i], it supports a wide range of data types such as:
- Structured data: Relational databases and tabular sources like comma-separated values (CSV) files
- Semi-structured data: JavaScript Object Notation (JSON), eXtensible Markup Language (XML), Apache Avro, and Apache Parquet
- Unstructured data: PDFs, images, and documents—processed through OCR and Document AI
Openflow’s role in enabling metadata-driven automation
At the heart of PolarSled Ingestion Framework is Openflow, which facilitates ingestion through:
- Pre-built, parameterized processor groups: These enable reusable logic and scalable pipeline management without the need for redundant configurations.
- Snowflake native app user interface: This UI simplifies pipeline creation and makes management accessible to engineers without deep coding expertise.
- Openflow_DB: This central metadata store improves pipeline observability, encourages collaboration, and supports efficient onboarding of new data sources without major rewrites.
- Snowflake native notifications: Custom alerts help monitor pipeline failures or slowdowns in real time, enabling prompt corrective actions.
This architecture enables data engineers to design and manage pipelines with ease, without writing extensive custom code.
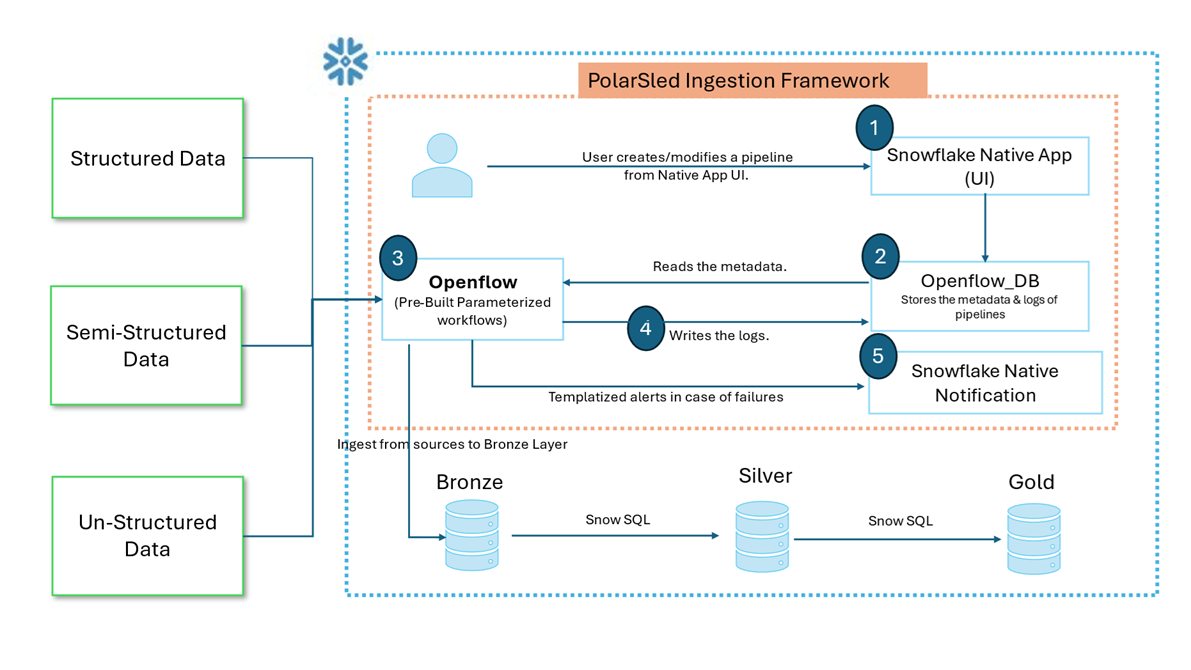
PolarSled Ingestion Framework – High Level Architecture
Dynamic execution with parameter context
A key innovation in PolarSled Ingestion Framework is its use of Parameter Context[ii], which allows dynamic execution of processor groups based on runtime metadata. This enables:
- Reusability: Shared logic across multiple pipelines. One processor group is reused for ingesting data from various sources into Snowflake, such as different APIs, eliminating the need for new pipelines for each source.
- Flexibility: Adapt to new sources or formats without code changes. Adding a new source, like audio files can be integrated by adding specific processor logic without impacting existing workflows.
- Scalability: Effectively manage numerous pipelines with minimal overhead. This eliminates the necessity of creating an ingestion pipeline for each dataset sourced individually. Simply add the metadata through the user interface provided by the native application, and the data will be seamlessly loaded into Snowflake.
Why this matters for modern data teams
Together, Openflow and PolarSled Ingestion Framework deliver a powerful set of capabilities:
- Metadata-driven workflows: Ingestion logic is defined through configuration tables instead of code, facilitating faster data delivery.
- Scalability and reusability: Build once and reuse universally by utilizing parameterized processor groups to manage a specific ingestion pattern.
- Enhanced governance: Centralized logs and metadata improve data lifecycle optimization and support regulatory compliance.
- Operational simplicity: As a fully Snowflake-native solution, PolarSled requires no additional infrastructure in Snowflake-managed virtual private clouds (VPCs).
- AI readiness: Built-in integration with Snowflake Cortex allows seamless use of large language models (LLMs) and machine learning (ML) tools—making it ideal for AI-powered document processing
Rethinking ingestion for the AI era
As enterprises shift toward AI-driven insights, the ability to scale data ingestion efficiently becomes critical. The PolarSled Ingestion Framework—powered by Openflow—offers a robust and extensible foundation. With its focus on metadata-driven workflows, built-in alerts, and support for diverse data types, it positions organizations to modernize their data architecture with confidence.
Those exploring ways to transform their ingestion strategy will find PolarSled a valuable step toward scalable, intelligent operations. LTIMindtree continues to support its development and implementation as part of broader enterprise modernization journeys.
Citations
[i] Openflow use cases, Snowflake: https://docs.snowflake.com/user-guide/data-integration/openflow/about#use-cases
[ii] Apache NiFi – use of Parameter Context: https://nifi.apache.org/docs/nifi-docs/html/user-guide.html#parameter-contexts
Blogger's Profile

Srikanth Singh Bidhaniya
Principal - Data Engineering, LTIMindtree
Srikanth is a seasoned data professional with nearly 17 years of experience in designing and building scalable data architectures. He brings deep expertise in data, analytics, machine learning, and artificial intelligence. In his current role, he leads product and accelerator development within the Snowflake Center of Excellence.
More from Srikanth Singh Bidhaniya
In today's data-driven world, a significant portion of valuable information lies locked within…
In this article, we will understand how the data platforms have evolved, identify key challenges…
Latest Blogs
Introduction There is a lot of noise around Agentic AI right now. Every headline seems to…
Traditionally operations used to be about keeping the lights on. Today, it is about enabling…
Generative AI (Gen AI) is driving a monumental transformation in the automotive manufacturing…
Organizations are seeking ways to modernize data pipelines for better scalability, compliance,…
