


Gen AI Data Readiness Using Qlik Talend Cloud (QTC)
Introduction
Generative AI is changing the way organizations tap into their data, moving beyond reports and dashboards to create insights, narratives, and even strategies in real time. Yet, preparing data pipelines that can harness both structured data (databases, ERP systems) and unstructured data (documents, PDFs, or images) for Gen AI applications often proves to be complex, time-intensive, and resource-heavy.
This is where Qlik Talend Cloud (QTC) for AI applications becomes a game changer. QTC’s AI-ready data tools are designed to simplify and accelerate this process, helping customers prepare their data for generative AI applications powered by large language models (LLMs) with retrieval-augmented generation (RAG).
The Challenges of preparing data for Gen AI
Integrating data from diverse formats and systems, ranging from enterprise platforms to legacy and cloud environments, creates significant obstacles for seamless processing and accessibility. Among the most common challenges are:
- Diverse data sources (structured, unstructured, and semi-structured)
- Enterprise systems (ERP, CRM, SAP, etc.)
- Cloud storage systems (AWS S3, GCS, Azure Blob)
- On-premises legacy systems
- Ensuring data availability for AI models
- Manual coding and integration overheads
Key backgrounds: LLMs, RAG, and Vector stores
Before examining the advantages of QTC, it’s useful to understand the enabling technologies that power Gen AI pipelines.
Large language models (LLMs) are trained on vast amounts of text to process, generate, and understand human language. They perform tasks such as generating content, answering questions, summarizing documents, or translating text.
Qlik Talend support
Here, QTC for AI applications supports providers such as Amazon Bedrock, Azure OpenAI, OpenAI (ChatGPT).
Data can be loaded into LLMs using two main strategies:
- Structured Data Loads
- Data load from relational DB, SaaS apps, files, etc.
- Incremental and history data loads
- Transform data before loading into LLMs
- Unstructured Data Load
- Load documents, PDF, emails, etc.
- QTC automatically chunks data and embed using LLM embeddings
- Loads embeddings into vector databases like Pinecone, OpenSearch, Snowflake Cortex, etc.
Retrieval augmented generation (RAG) is a method that boosts the performance of generative AI models, especially large language models (LLMs), by connecting them to an external knowledge source. This improves the accuracy, relevance, and freshness of their responses. RAG fills the gap between what an LLM knows, and the specific, up-to-date information needed in real-world applications like chatbots and virtual assistants.
Qlik Talend support
QTC provides a built-in RAG assistant, a plug-and-play Gen AI assistant that developers can use for queries and responses.
Vector database stores embeddings (numeric representations of text, images, or audio) that allow for rapid similarity searches. They are critical for AI-driven applications like recommendation systems and pattern recognition.
Qlik Talend support
Aids below vector stores using native connections to:
- PineCone 2. OpenSearch 3. ElasticSearch 4. Cortex, 5. Databrics Mosaic
- End-to-end support for parsing, chunking, embedding, and indexing of data before storing it into vector store using AI-ready data tasks.
Qlik Talend Cloud: A breakthrough for AI readiness
QTC is built on Qlik’s cloud platform and is designed to ensure reliable data for AI, analytics, and business operations. It provides a complete set of tools for data integration and quality, helping data engineers and scientists create AI-powered data pipelines that deliver trusted data wherever it’s needed.
It helps solve AI-related challenges by providing AI-ready data tools. These tools make it easier and faster for customers to prepare and move their data into generative AI applications that use LLMs with retrieval-augmented generation (RAG). QTC also simplifies the process of building Gen AI data pipelines.
Key features include:
- QTC pipelines for AI: QTC is designed to build data integration pipelines faster for RAG-based generative AI applications. It uses a low-code or no-code approach, helping teams streamline the setup without needing deep technical expertise.
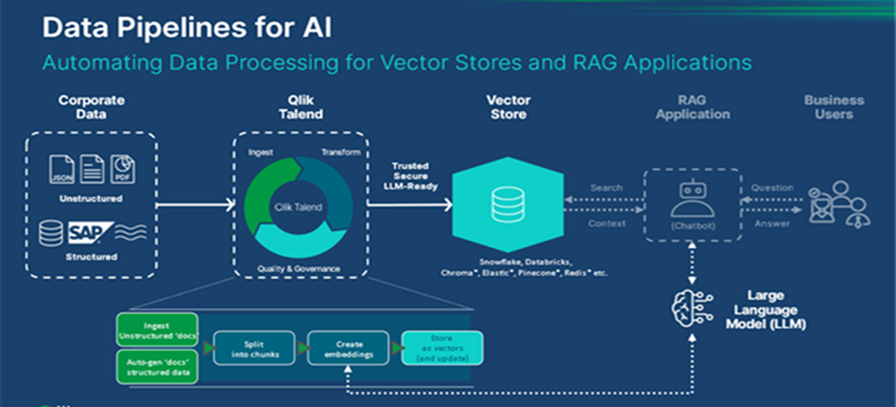
- Source connectivity: It provides no-code access to hundreds of data sources, including enterprise systems, mainframes, SAP, databases, and SaaS apps. It supports efficient, low-impact data movement using near real-time log-based change data capture (CDC) or incremental APIs. This means only new or changed data is sent, avoiding repeated full data loads from source to target.

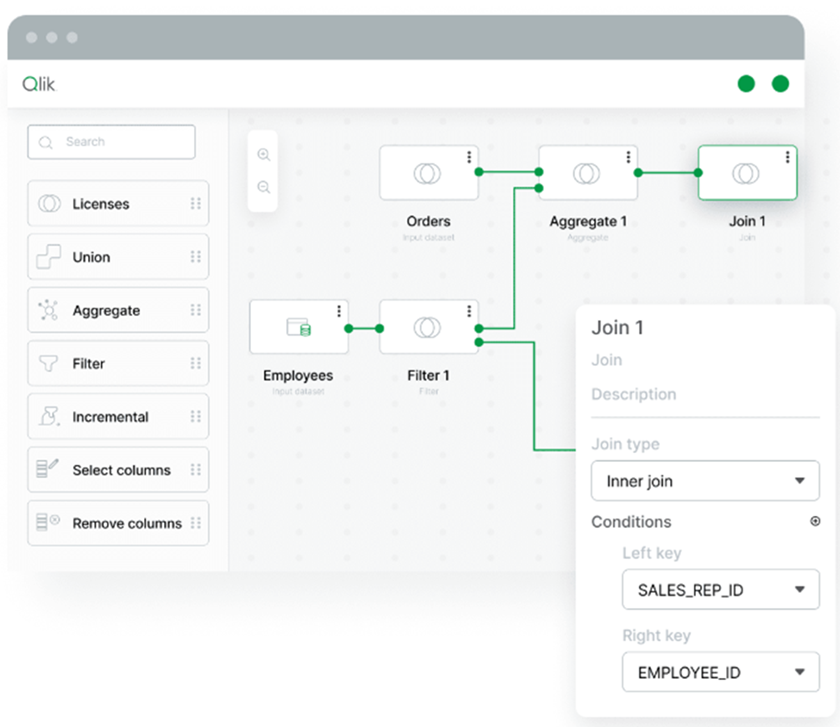
- Data transformation: Once the data reaches the target cloud platform, the next step is to prepare it for vectorization. This involves creating new datasets by joining and filtering the right fields and records. This way only the most relevant data is passed to the LLM. QTC supports this with a flexible transformation design experience from easy no-code transformation flows to advanced Gen AI-assisted query building for developers.
Check the image below for example.
- Data modelling: After the required datasets are created, the next step is to define relationship metadata between them. This helps the AI-ready data process understand how different pieces of data are connected. This makes it easier to identify useful building blocks for generating documents. These documents are then prepared and stored in a vector database for use in generative AI applications.


- Vector embeddings: Automatically create vector embeddings from text data to make it easier to find similar content and organize it into categories.
- Low-code or no-code approach: QTC offers an easy-to-use interface that allows users build data pipelines without needing to write a lot of code. This opens access to advanced AI features, enabling more teams to take advantage of generative AI.
- Automation: By automating important steps, QTC helps reduce the time and effort needed to get data ready for gen AI applications. This includes tasks like collecting data, transforming it, and loading it into vector databases for use with LLM embeddings.
- Data Integration: QTC works with many different data sources and destinations, making it easy to connect with your existing data systems. Whether you’re using structured databases or unstructured data stored in the cloud, QTC helps you integrate everything smoothly.
Qlik Talend Cloud enables organizations to
- Ingest data effortlessly from enterprise systems, cloud storage, and even legacy platforms without heavy lifting.
- Clean and transform diverse data types—structured, semi-structured, or unstructured, so they’re AI-ready.
- Automate repetitive tasks like mapping, table creation, and data instantiation, reducing manual effort.
- Boost AI and ML productivity with a flexible no-code/pro-code environment, accelerating deployment of analytics-ready structures.
Conclusion
With QTC for AI applications, organizations can bridge the gap between fragmented data systems and Gen AI ambitions. By removing the friction from ingestion, transformation, and embedding, QTC clears the path for building scalable, AI-ready pipelines. Instead of wrestling with fragmented systems and manual work, organizations can focus on creating real business outcomes with AI. It’s less about the plumbing and more about enabling ideas to scale.
References
- Simplifying GenAI Data Pipelines with Qlik Talend Cloud, Qlik Community, December 18, 2024:
- Create a Data Model, Qlik Documentation:
- Connecting to LLM connections, Qlik Documentation:
Blogger's Profile

Shivakasayya Gaddagimath
Associate Principal – Data Engineering, LTIMindtree
Shivakasayya Gaddagimath is an Associate Principal – Data Engineering in LTIMindtree’s Data & Analytics practice. With over 17 years of experience in data and application management, he has spent more than 15 years specializing in implementing Informatica Data Integration Pipelines across both on-premises and cloud environments.
Latest Blogs
Introduction There is a lot of noise around Agentic AI right now. Every headline seems to…
Traditionally operations used to be about keeping the lights on. Today, it is about enabling…
Generative AI (Gen AI) is driving a monumental transformation in the automotive manufacturing…
Organizations are seeking ways to modernize data pipelines for better scalability, compliance,…
