


Beyond Data Catalogs: Why Metadata Fabrics Are the Upgrade You Need
If your data feels like a messy attic full of stuff you might need but can never find, it’s time for an upgrade.
You know how your phone has thousands of photos, but when you want that one picture from last year’s trip, you can’t find it because it’s buried somewhere between memes and screenshots of recipes you never cooked?
That’s how it is with data. We have tons of it, but without the right context — the “story” of the data — it’s just noise. That “story” is called metadata. And managing it well is the difference between “Oh yeah, found it instantly” and “Wait… where did I even store that?”.
Enter metadata fabric — the cooler, more connected cousin of the old-school data catalog.
So, what exactly is a metadata fabric?
Imagine your metadata is scattered across dozens of different cupboards, drawers, and shoeboxes in your house. You know it’s all there but finding anything is a Herculean task.
A metadata fabric is like suddenly having a magical walk-in closet where everything is neatly organized, labelled, and — bonus — it’s connected to every other closet you own. You just walk in, grab what you need, and get on with your day.
It’s not just about storing metadata — it’s about weaving it together, so it actually makes sense and works for you.
The “secret recipe” behind metadata fabric
Here’s what makes the magic happen:
- Interoperability: All your systems finally speaking the same language. No more awkward “lost in translation” moments.
- Standardization: Everyone calling things by the same name. Because “customer_id” and “client_number” should mean the same thing.
- Automation: Letting the system handle the boring parts, like constantly updating metadata, so you don’t have to.
- Integration: All your tools talking to each other instead of working in their own little bubbles.
- Sustainability: Built to keep working even as your data grows, changes, and gets a bit moody over the years.
Why metadata fabrics are a big deal
Alright, here’s the cheat sheet for why you might actually fall in love with this thing:
- One view to rule them all: All your metadata, one screen, no scavenger hunts.
- Permanent IDs: Like giving each dataset its own social security number so you always know who’s who.
- Data backstory: See where it came from, who’s used it, and how it’s changed over time.
- Version history: Like “track changes” for your data, so nothing sneaks past you.
- Security smarts: Control who can see or use data like a velvet rope at an exclusive club.
- Google-level search: Actually find stuff when you search for it.
- Plays well with others: Works with catalogs, analytics tools, visualization platforms–basically, the extrovert of the data world.
Real-life benefits (a.k.a. why you’ll sleep better)
Implementing metadata fabric has several advantages:
- Improved data management: Organizes metadata in a structured and consistent manner.
- Enhanced collaboration: Facilitates data sharing and understanding among teams.
- Better data quality: Tracks changes and ensures metadata accuracy.
- Time-efficiency: Automates metadata tasks, saving time and reducing errors.
- Scalability: Supports large and growing datasets across multiple domains.
- Compliance support: Helps organizations meet regulatory and data governance requirements.
Metadata fabric vs. data catalog: The family drama
Think of a data catalog as a really nice, well-organized address book. You can look up names, see basic details, and maybe jot down a note or two.
A metadata fabric? That’s your entire social network. Not only do you have the names, but you also know the connections, the history, the photos, the mutual friends, and you get updates in real-time. Basically, it’s alive.
This table details how a metadata fabric goes beyond a data catalog:

Table 1: Data catalog vs metadata fabric
Architecture patterns
Here are different metadata architecture patterns:
| Traditional metadata architecture | Distributed metadata fabric architecture |
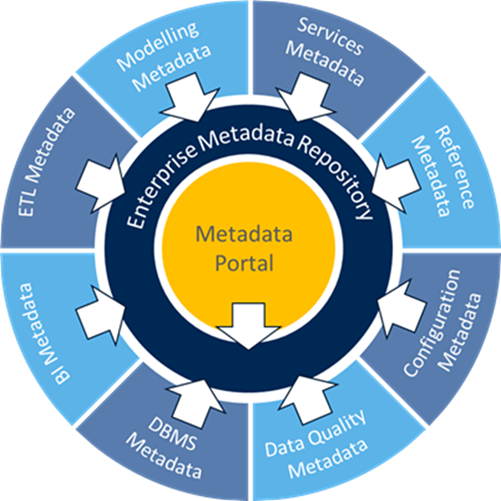 A single metadata repository that contains copies of metadata from various sources. Organizations seeking a high degree of consistency within the common metadata repository can benefit from this architecture. A single metadata repository that contains copies of metadata from various sources. Organizations seeking a high degree of consistency within the common metadata repository can benefit from this architecture. | 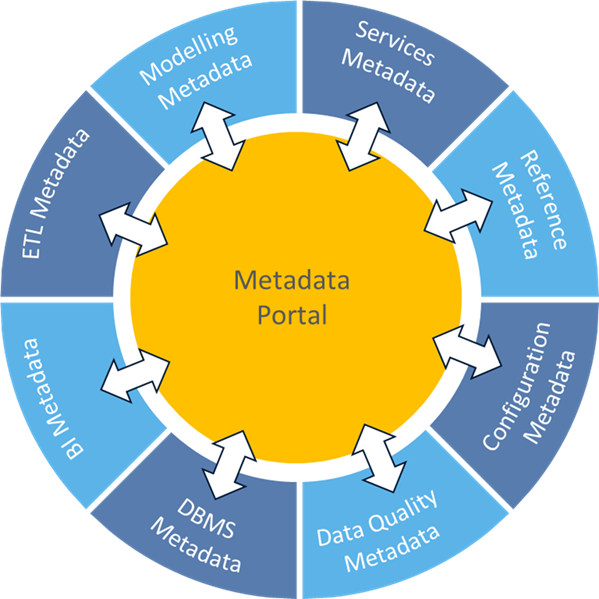 There is no persistent repository. The metadata management environment maintains the necessary source system catalogues and lookup information needed to process user queries and searches effectively. There is no persistent repository. The metadata management environment maintains the necessary source system catalogues and lookup information needed to process user queries and searches effectively.
|
| Hybrid metadata fabric architecture | Bi-directional metadata fabric architecture |
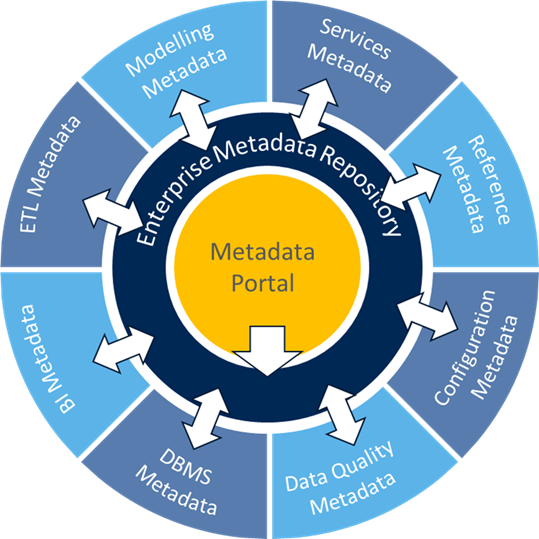 A hybrid architecture combines characteristics of centralized and distributed architecture. Metadata still moves directly from the source systems into a centralized repository. However, the repository design only accounts for the user-added metadata, the critical standardized items, and the additions from manual sources. A hybrid architecture combines characteristics of centralized and distributed architecture. Metadata still moves directly from the source systems into a centralized repository. However, the repository design only accounts for the user-added metadata, the critical standardized items, and the additions from manual sources. | 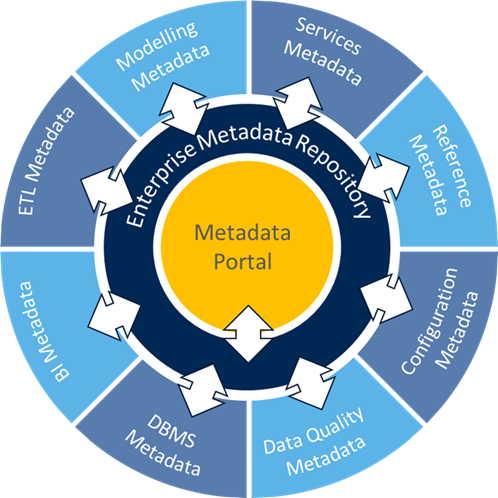 Bi-directional metadata architecture allows metadata to change in any part of the architecture (source, data integration, user interface) and then feedback is coordinated from the repository (broker) into its original source. Bi-directional metadata architecture allows metadata to change in any part of the architecture (source, data integration, user interface) and then feedback is coordinated from the repository (broker) into its original source.
|
Conclusion
Metadata fabric isn’t just a tech upgrade — it’s a way to keep your data life from spiraling into chaos. It connects the dots, fills in the backstory, and makes sure you can actually use your data instead of just collecting it like digital clutter.
So, if your current data setup feels like a junk drawer, maybe it’s time to weave yourself a metadata fabric.
References
- Market Guide for Metadata Management Solutions, Gartner, 03 September 2024, https://www.gartner.com/en/documents/5730683
Blogger's Profile

Manojit Saha
Associate Principal- Data Engineering, LTIMindtree
With over 20 years of global experience in data and analytics architecture and advisory, Manojit is a trusted expert in guiding organizations through their data modernization journeys. He combines a design thinking mindset with deep expertise across both legacy systems and modern data stacks to craft resilient, future-ready data strategies, roadmaps, and architectures. His ability to translate complex business challenges into sustainable technical solutions makes him a key partner in digital transformation initiatives.
Latest Blogs
Introduction There is a lot of noise around Agentic AI right now. Every headline seems to…
Traditionally operations used to be about keeping the lights on. Today, it is about enabling…
Generative AI (Gen AI) is driving a monumental transformation in the automotive manufacturing…
Organizations are seeking ways to modernize data pipelines for better scalability, compliance,…
