


The Definitive Upgrade: Seamless Migration of a Recursive Apache Spark Solution to Snowflake
Organizations are seeking ways to modernize data pipelines for better scalability, compliance, performance and also to avoid vendor lock-in. In this context, we evaluated the migration of a material and batch genealogy data pipeline from a Spark-based environment to Snowflake. The objective was to leverage Snowpark Connect to run existing Spark code with minimal changes directly on Snowflake, thereby simplifying recursive logic, multi-level processing, and improving overall efficiency.
This blog explores how Snowpark Connect streamlines Spark workloads and how tools like the Snowpark Migration Accelerator (SMA) help assess Spark code compatibility for a smooth transition.
Material and Batch Genealogy Use Case: Challenges and Complexity
Consider the use case of a major pharmaceutical and healthcare organization that had a critical requirement of material and batch traceability to meet regulatory, quality, and compliance needs. They needed clear visibility into product lineage across manufacturing stages and systems.
To address this, they had built a material and batch genealogy solution on Spark that traced complex parent–child relationships across multiple levels, integrating data from five ERP systems and visualizing lineage using Neo4j graphs.
Key technical challenges in the Spark environment were:
- The Single-SKU Bottleneck: The Spark job was initially designed to handle one finished good stock keeping unit (SKU) per run. Scaling this to process all the SKUs under a brand in one go significantly increased the data volume and complexity, potentially straining the Spark cluster.
- The Multi-ERP Data Integration Nightmare: Combining records from five ERP systems (each with their own batch IDs and parent-child linkages, including splits and merges) required significant data merging logic resulting in multiple joins in memory, requiring necessary fine-tuning on the cluster.
- Unsustainable Operational Debt and Compliance Complexity: In the pharmaceutical industry GxP compliance is essential. This requires maintaining strong change control processes, validating code, ensuring environment consistency, and keeping thorough audit trails. Managing Spark clusters including their configurations and versions, as well as handling separate data outputs to Neo4j, further increases operational complexity.
Why Consider Snowflake? Snowflake was strategically chosen as the alternative execution platform to directly address the critical challenges inherent in the legacy Spark environment. The core strategy was not a complete replacement, but rather an optimization paradigm: leveraging the superior performance and scalability of the Snowflake Data Cloud to execute the existing Spark code more efficiently and reliably via Snowpark Connect.
Snowpark Connect for Apache Spark–Use Your Spark Code on Snowflake
Snowpark Connect[i] is a new capability that allows Spark developers to run their existing Spark code directly on Snowflake’s compute engine. In essence, Snowflake becomes the “Spark cluster.” You connect your Spark application to Snowflake and Snowflake executes the DataFrame operations internally. This offers a few transformative benefits:
- Zero Spark Cluster Management: A core benefit of this architectural shift is that computation is handled entirely by Snowflake’s fully managed virtual warehouses, freeing the team from the complexities of provisioning and tuning external Spark infrastructure.
- Seamless Spark Code Migration with Minimum Changes: Because Snowpark Connect implements the Spark DataFrame API on Snowflake, the PySpark code can largely remain intact. You may only need to adjust the Spark session initialization to use the Snowflake Spark Connect client and provide Snowflake connection settings.
- Automatic Performance Amplification / Unlocking Native Engine Efficiency: Snowflake’s vectorized execution engine will handle the heavy lifting. For example, hints like DataFrame.hint() or manual repartition calls in Spark are simply ignored by Snowpark Connect. Snowflake’s optimizer automatically determines the best execution plan. This means you will get improved performance out-of-the-box without low-level tuning.
- Centralized Governance and Compliance: Snowflake is built with enterprise governance in mind so role-based access control, detailed logging, data encryption, time travel, etc., are built-in. By moving the pipeline into Snowflake, the entire process inherits Snowflake’s governance. This makes it easier to enforce GxP compliance due to one platform to validate, with immutable data history and fine-grained security controls.
Snowpark Migration Accelerator: Assessing Spark Code Compatibility
Before jumping straight into running our Spark code on Snowflake, it’s prudent to analyze how compatible that code is with Snowpark Connect-supported features. This is where Snowpark Migration Accelerator (SMA) comes in. Snowpark Migration Accelerator is a free code scanning and conversion tool from Snowflake that helps migrate Spark applications to Snowpark (Snowflake) execution.
Below is the checklist you may follow for migrating Spark workloads on Snowflake.
- Conduct the assessment using SMA to obtain a compatibility report, which will help identify any critical issues within our Spark code.
- Do a trial run with Snowpark Connect on a Snowflake dev environment. If something fails, refer to SMA’s report for clues (e.g., an unsupported API call).
- If Snowpark Connect runs the code well, the goal was achieved with near-zero refactoring.
- If there are problematic aspects, either adjust them in the Spark code or use SMA’s converted code as a reference for a targeted rewrite of that part to Snowpark API.
Architecture Overview: Transition from Apache Spark to Snowflake for Processing
The following architecture illustrates the transformation in the processing engine for this use case, where Apache Spark has been effectively replaced by Snowflake. Previously, Spark clusters managed the entirety of data processing, requiring extensive configuration, tuning, and maintenance from the team.
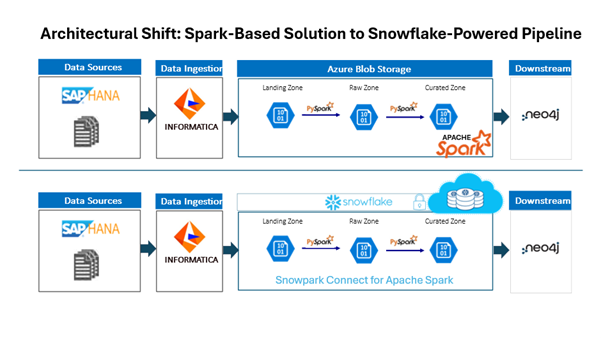
With the adoption of Snowflake, the execution paradigm shifts fundamentally. The Spark application now connects directly to Snowflake using Snowpark Connect, offloading all DataFrame operations to Snowflake. Virtual warehouses within Snowflake manage the computational workload, automatically scaling resources as necessary and optimizing execution plans without manual intervention. This not only eliminates the operational overhead of Spark cluster management but also leverages Snowflake’s built-in features for security, compliance, and data governance.
The revised architecture centralizes data processing, governance, and compliance within Snowflake, streamlining the workflow and enhancing reliability. The Spark codebase remains largely intact, requiring only minor modifications for connectivity, while benefiting from Snowflake’s performance and scalability. This new structure enables the team to meet regulatory requirements efficiently and focus on business logic rather than infrastructure management.
Conclusion
In summary, Snowpark Connect provides a compelling path to modernize Spark-based batch pipelines without a costly rewrite, combining the familiarity of Spark with the strengths of Snowflake. This enables you to overcome Spark’s limitations. With the Snowpark Migration Accelerator for guidance and automated conversion, the migration can be accelerated and de-risked, yielding a faster, more scalable, and compliant solution ready for production deployment.
References
[i] Snowpark Connect for Spark, Snowflake Documentation
https://docs.snowflake.com/en/developer-guide/snowpark-connect/snowpark-connect-overview
Blogger's Profile

Yogaraj Kathirvelu
Principal – Data Engineering, LTIMindtree
Yogaraj is a data professional with 20 years of experience in building data architectures and creating automation frameworks. He is passionate about data and analytics. In his current role, he leads the development of products and accelerators within Snowflake practice.
Latest Blogs
Traditionally operations used to be about keeping the lights on. Today, it is about enabling…
Generative AI (Gen AI) is driving a monumental transformation in the automotive manufacturing…
In the era of Industry 4.0, automation, robotics, and data-driven decision-making are dominating…
Introduction Imagine your sales team spending hours entering order details from emails into…
