


Inside Kimi K2 Thinking: How Safe Is Open Agentic AI for Enterprises
A closer look at Kimi K2 Thinking, an open agentic model that pushes autonomy, security, and large-scale tool use for enterprises.
The rise of long-context language models and reasoning models has altered my perspective on agentic AI. Teams now expect these systems to plan and execute multi-step tool use, handle sensitive actions, and run complex workflows across the software development lifecycle (SDLC), including incident triage and end-to-end remediation.
Yet many industry reports show that reasoning models still struggle to do this reliably. They mis-invoke tools, bypass guardrails in large workflows, and fail to capture long-horizon dependencies across hundreds of steps.
These tools are also slow and expensive to run in real enterprise settings. The AI community has been asking a simple question: “Can a model ever act as a full-fledged autonomous agent, planning, executing, and correcting itself over hundreds of steps without compromising safety?” Then came Kimi K2.
A model gaining fast attention. However, from an enterprise lens, Kimi’s current safety and governance posture should concern CISOs, CTOs, and board members who want to bring such models in-house.
How Kimi K2 Transforms the Open Reasoning Landscape
Released quietly in July 2025, Kimi K2 arrived as an open-weight Mixture of Experts (MoE) model with 1 trillion total parameters and 32 billion active at a time, in Base and Instruct variants, pretrained on 15.5 trillion tokens.
An open-weight model can be downloaded by an IT team, fine-tuned, and run in their local environments. MoE means only a small set of expert networks fire on each token, so you get high capacity without paying for all parameters on every step.
How It Performs in Actual Agent Workflows
In my tests, the base Kimi K2 model shows strong performance across coding, mathematics, tool use, and general language tasks. The Instruct variant performs even better on code-heavy agent workflows, such as the Software Engineering (SWE) Bench Verified and LiveBench,1 where it outperforms most other open-weight models and even some closed models on complex fixes
The architecture and training choices clearly favor fast and accurate execution over long, speculative reasoning. I see this whenever I push this model to explain itself. It wants to move to tools and actions quickly, which is helpful for agents, but also easy to misuse if one is not careful.
Kimi K2 can also track state across hundreds of external API calls or functions without requiring human intervention to guide every move. This makes it on-premise deployable for enterprises.
Benchmarks position Kimi K2 Thinking near leading proprietary models from Google, Anthropic, and OpenAI. Compared to DeepSeek V3, Kimi K2 utilizes a larger number of total parameters, 1.04 trillion versus 671 billion, and a larger pool of experts, 384 versus 256, as determined by a sparsity scaling study.2
Kimi also halves the number of attention heads, from 128 to 64, to reduce the cost of long sequence inference. This is attractive for agent workloads that need long context windows and frequent tool calls. Kimi K2 Thinking has effectively created a new class of open models that act as autonomous agents with transparent reasoning traces that can be inspected.
For enterprise leaders, these numbers send a clear message. You can now get near top-tier reasoning power in your own stack at a fraction of past cost, but nothing in these benchmarks measures governance, misuse, or blast radius. That gap is where the real risk, and the real design work for CISOs and CTOs, now begins.
How Kimi K2 Learns to Behave Like an Enterprise Agent
Kimi K2 performs well in agent-like scenarios, primarily due to its training on large-scale simulations of tool use. From the model card and my own experiments, it is clear that the team utilized automated environments that combine real and synthetic tools around sampled user tasks, such as opening and closing incidents, updating tickets in an IT service tool, changing records in a CRM, or triggering CI or deployment jobs.
An internal LLM-based judge scores the traces against the rubric and keeps only the high-quality runs. This dataset, combined with on-policy learning and self-supervised reinforcement learning, teaches the model general patterns for planning and calling tools in the correct order.
Even with that level of training, enterprises still need to proceed with caution when adopting open-source models without robust security controls.
In one client discussion, I remember, a team attempted to wire an open model directly into their incident routing process. The model started pulling complete log lines, including sensitive data, into its reasoning traces and suggested incorrect escalation paths. The issue was identified early in testing, but it highlighted how quickly autonomy can become exposed.
Similarly, Kimi K2 Thinking introduces several operational risks that enterprises must manage, as it can operate across long tool chains, interact with sensitive systems, and run within environments where there is no native guardrail layer. Risks such as:
Long Tool Chains Create Failure Cascades
A single incorrect API or tool response can mislead downstream steps, causing failure cascades across long, multi-step workflows that involve up to 50–300 tool calls. It can corrupt data. Unverified access to critical information can easily lead agents toward faulty decisions. Robust verification layers are essential to prevent these failure cascades.
Over Reflection and Infinite Reasoning
Loops Kimi-K2 model’s deep introspection can lead to overthinking. It can cause delays, infinite loops, and higher compute costs. Besides, its heavy-mode parallel aggregation increases computing cost and latency. So, guardrails like reflection budgets, timeouts, token limits, and step-checkpointing are essential to keep it efficient and controlled.
No Native Governance Layer
Since K2 is fully open-weight and ships with no native security or governance controls, enterprises must supply their own compliance filters, moderation layers, permission boundaries, and data-governance safeguards.
On-Premises Deployment Risks
Open-weight or self-hosted deployments introduce additional risks, including regulated data exposure, prompt injection, model misuse, version drift, and non-compliance with the General Data Protection Regulation (GDPR) and the Health Insurance Portability and Accountability Act (HIPAA). Thus, making robust machine learning operations (MLOps) and governance pipelines is essential.
Yet these risks are not entirely ignored in the design. Alongside its agent behavior, the Kimi K2 family includes a dedicated post-training safety component.
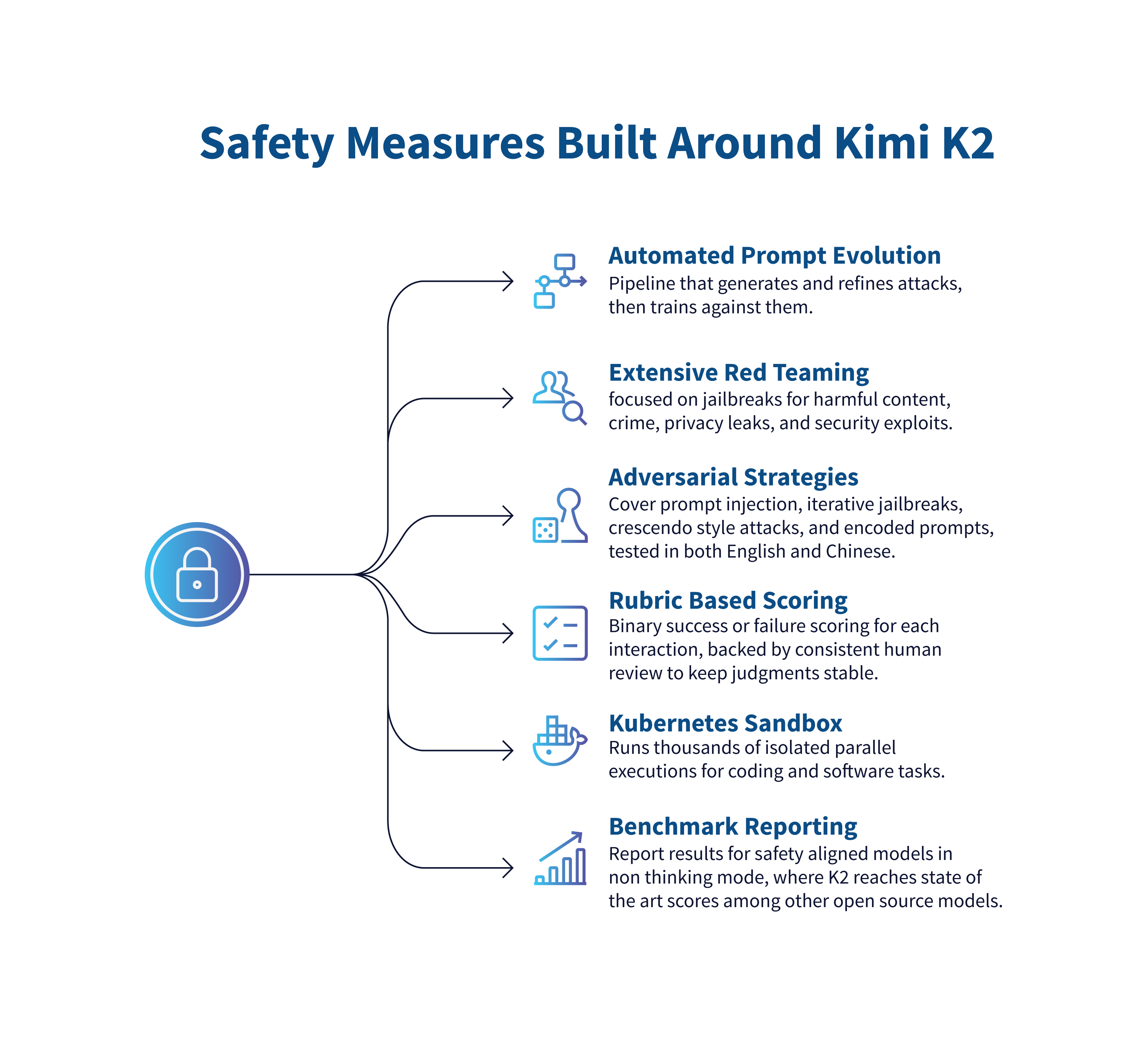
Figure 1: Safety measures ensuring Kimi K2 for enterprise security
Conclusion
Kimi K2 Thinking is efficient to run, requiring approximately 24 GB of VRAM for Integer 4-bit serving, and provides clear reasoning traces that expose its plans, tool choices, and reflections.
It brings strong agent behavior into reach for teams that want open models in their own stack. However, I have a few observations that CISOs and AI platform leaders should consider if they want a secure and predictable path to adoption.
In my work at BlueVerse, I see this clearly when we design guardrails for our own AI agents, so they behave safely inside enterprise systems.
- Treat Kimi K2 as a powerful but narrow tool, not a general-purpose reasoning engine. On challenging or loosely defined tasks, it can generate long traces, exceed token limits, and leave tool calls or outputs incomplete.
- Enable tool use only when a task needs it. I’ve observed that it performs best within a guided coding or automation workflow, rather than as a one-shot code author for complete projects. At BlueVerse, we follow the same approach. We map each agent’s skill to a precise task boundary, ensuring the model does not overextend its capabilities.
- Plan for safety, governance, and compliance from the start. The teams that benefit from Kimi K2 will be those that design guardrails, monitoring, and approval paths early, rather than adding controls after deployment.
One more point to consider. Open models reduce vendor dependence, but they also shift full accountability for safety and failure handling onto your own engineering teams.
References
1Kimi K2 Open Agentic Intelligence, Kimi Team, MoonShot, July 28, 2025: https://moonshotai.github.io/Kimi-K2/
2Introducing Kimi K2 Thinking, Kimi Team, MoonShot: https://moonshotai.github.io/Kimi-K2/thinking.html?
3Kimi k1.5: Scaling Reinforcement Learning with LLMs, Kimi Team, MoonShot, June 3, 2025: https://arxiv.org/pdf/2501.12599
Blogger's Profile

Dr. Joyita Chakraborty
Dr. Joyita Chakraborty, Data Scientist, BlueVerse, LTIMindtree
Dr. Joyita Chakraborty is a Data Scientist at LTIMindtree with over 7 years of experience in applied data science, machine learning, and GenAI. She has published research in evolving networks, time-series analytics, anomaly detection, and the evaluation of agentic GenAI systems.
Latest Blogs
We live in an era where data drives every strategic shift, fuels every decision, and informs…
The Evolution of Third-Party Risk: When Trust Meets Technology Not long ago, third-party risk…
Today, media and entertainment are changing quickly. The combination of artificial intelligence,…
In our first blog, we examined the looming risk posed by quantum computers to existing asymmetric…
